I'm on a team with mainly full-stack developers and no dedicated database expert, and it's mostly serving us well. We realised, however, that we could use a few hints by a DBA. The specific advice probably doesn't apply to your situation, but the general idea of getting expert advice probably does.
Self-contained team — with the occasional lift
In general, I prefer a team of generalists over a team of specialists. It's just a lot more flexible to have many Jacks-of-all-trades that can work at all levels of the application — e.g., docker, database, back-end, front-end, design — than to have specialists in all the roles. Plus we all get to do all the things, learn about all the things, and that's just more fun (IMHO) than staying in our lanes.
But of course, nobody is an expert on everything.
That's why we generally recommend a team of T-shaped people. Not physically, of course (human shaped is prettier), but in terms of skills and specialization. The idea is that everybody has a broad enough knowledge of everything (that's the horizontal line in the capital T) to be useful, and then a few deep enough areas of expertise (that's the vertical line in the capital T). The ideal is that combined the team has a deep enough knowledge about all the critical areas of their work, and few enough bottlenecks to always focus on the currently most important stuff.
On our team, I'm lucky to work with people who know a lot more about UX and design than I do (otherwise we would be in trouble), but I know enough to pair up on a design task and run with it from there.
Similar with other parts of our work: simple tasks can be done by almost anybody, and if it gets a little harder, there is usually someone on the team with a deeper knowledge on the specific area to pair up with — leaving us with a solution to the problem at hand and on-the-job training for everybody.
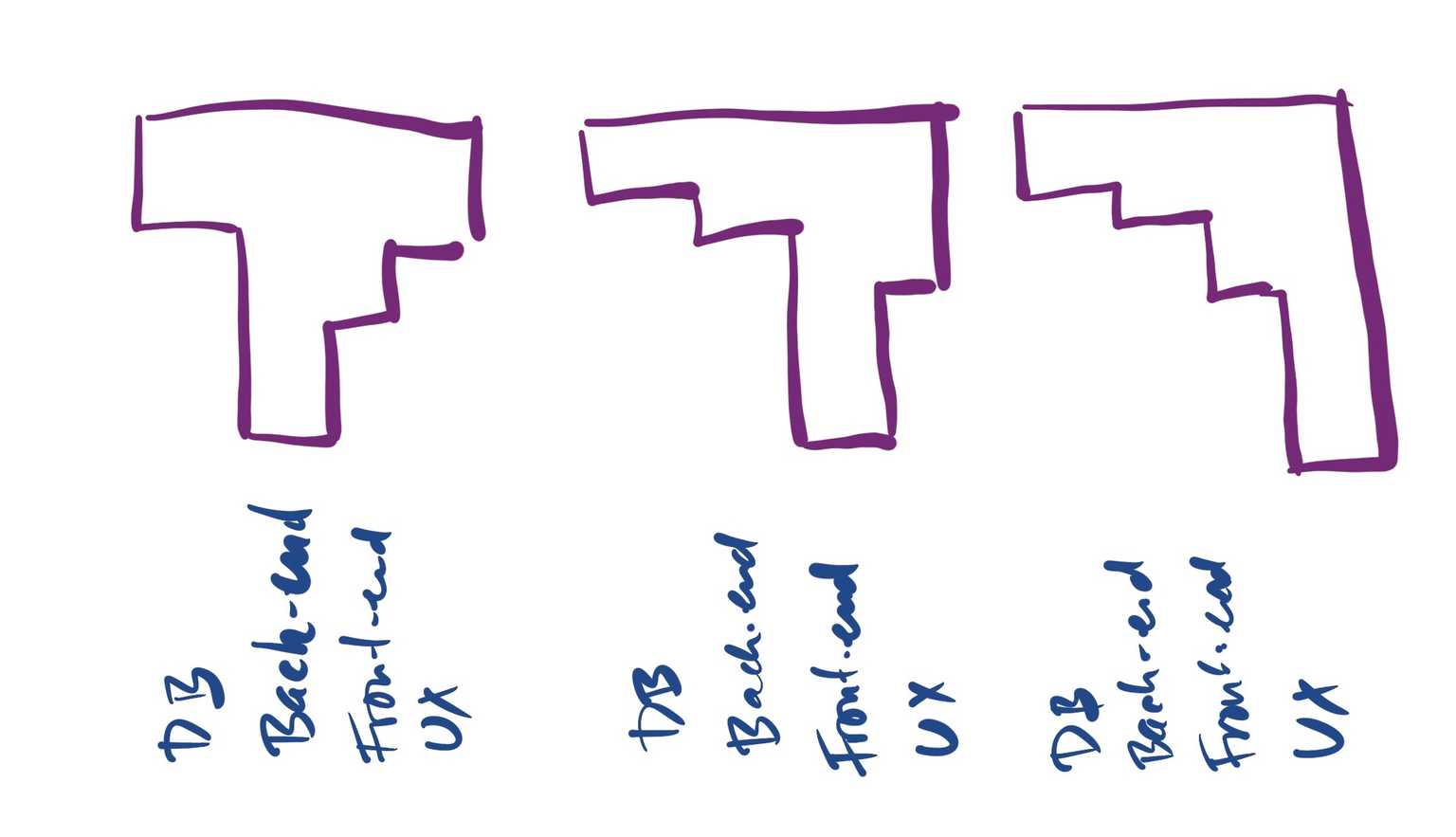
So that's what I mean by a self-contained team. Largely self-contained, that is, because we can still use the occasional help from someone with a T that goes really deep.
Our database "situation"
Now, a central component of our application is a database with a couple of million writes per day.
With seasoned developers on the team, we never felt we needed a dedicated database administrator. We pretty much know how to structure a database and write SQL, and we thought setting it up and running it was within our ability too.
Maybe a bit of hubris on our part, there.
The initial choice in 2018 was MySQL. When we began worrying about having the DB as a single point of failure, we first tried MySQL Cluster which crashed badly for us one summer. We moved on to MariaDB and Galera (the Internet liked them better) but still had problems, particularly with thousands of deadlocks per day, so we were not entirely comfortable. And after another crash (again a type of crash caused by clustering that a single database would have handled just fine), we decided to go simple and run a simple MariaDB instance as primary, with simple replication ensuring that we have a spare to swap to (with an acceptable amount of downtime).
This has been nice, simple, and stable. But maintenance is a challenge: when our primary database server is down, our systems are down.
Again, we turned to the internet and are now considering to add an extra layer to our setup, like a proxy between the applications and the database, so that we can swap the traffic around between database servers. MaxScale looks promising (albeit not free), a virtual IP or any type of proxy can probably also do the trick.
But once bitten, twice shy. The cluster setups that should help save our bacon caused problems before. (We were bitten twice, so I guess we're slow.) We decided that we'd like expert advice: what are the tradeoffs, what would be the safest way for us to proceed?
MariaDB to the rescue
MariaDB is open source, but it is also a company offering support and services, and we agreed on a two day remote session with one of their DBAs. Money well spent, if you ask me.
What we learned, specifically
Here are some things we learned, specific to our situation and our database.
Feel free to skip or gloss over this section if database specific stuff is not interesting to you. There is a section about my non-technical take-aways waiting for you at the end.
It was really helpful to look over our configuration and setup with an expert. We are mostly okay, but got a few suggestions for improvements.
- Most notably: if we don't turn on
log_slave_updates, the replicants cannot be promoted to master. Good to know.
Then we talked about our usage scenarios.
- Because of reasons[^Mostly good reasons, I promise!] that I won't go into now, we have a repeating pattern where a lots of threads in parallel are inserting in one table and summing up in another table, often with the same keys — which we already knew caused a lot of the deadlocks. That's a pattern where Galera is not a good fit. Good to know.
- MaxScale does seem like a good fit for our need, is easy to set up and configure for our needs, and we can trust it to be reliable. Good to hear from a real person understanding our usage, not just the marketing material.
- To avoid a single point of failure, we can set up two MaxScale instances, and configure the applications to connect to both.
And while we were at it, we also looked a bit on our slow queries and last deadlocks and learned a few things.
5. Indices help, of course, but they don't work if we are applying functions to what we are comparing. For instance, if a query has where date(something) > something_else — an index on something will not work.
6. If we have an index on (a,b,c), we don't need indices on (a,b) and (a), because the first one will be used instead of the two last ones anyway. Better not having them, so we are not wasting cycles updatign them.
7. We have a lot of inserts using select instead of values because we are calculating and looking up values as part of the one-line sql statements. This means the inserts are always treated as bulk statements, even when they are only inserting one line. Bulk inserts take a table lock in order to pick a primary key — so that's another big source of deadlocks for us. News to me! We can probably split those up into a select looking up the values, and then a simpler insert statement inserting with values. Great stuff, very specific to our weird use case.
What we learned, generally
I continue to believe that our strategy of having a team of T-shaped generalists serve us well, and although I'd certainly welcome more database expertise on our team, I still feel that we are well served by trying to be and becoming our own database experts — with the help of friends, former colleagues, and the Internet.
I also believe that having "a real expert" drop by for an in-depth discussion is really helpful. We got the peace of mind that we needed about the next iteration on our database setup. We got an understanding of why our previous setups didn't work. And we got good insights on how to improve a few critical database statements.
And I also think that the time we spent on our own trying to do this was important — if we did not know and understand our pain points, we would not be able to ask the right questions and understand the answers.
So: aim to have a self-contained team, but don't be afraid to call an expert for guidance — you might learn a lot.

